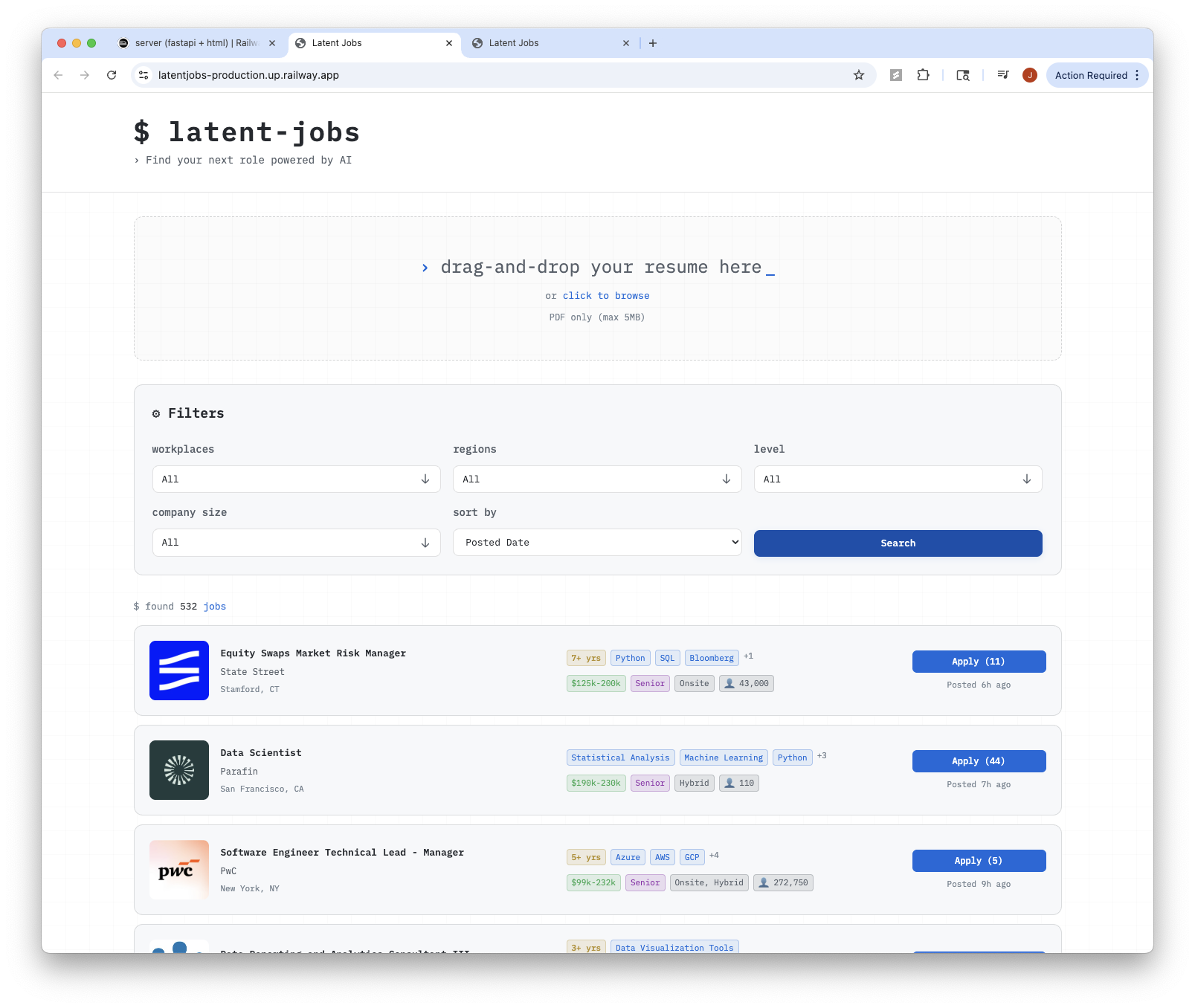
Latent Jobs
Job search aggregator with semantic resume matching. Scrapes LinkedIn and uses embeddings to rank jobs by relevance.
The Problem
LinkedIn's job search is keyword-based and doesn't account for how well a role matches your actual background. A resume highlighting "Python, ML, analytics" might match "Java backend developer" on keyword overlap despite being a poor fit. Candidates need semantic matching, not just string matching.
Technical Approach
The pipeline scrapes LinkedIn via a reverse-engineered API, then uses GPT-4o-mini via DSPy to extract structured metadata from each job: summarized descriptions, technologies used, workplace type, seniority level, salary ranges, and YOE requirements.
Jobs are embedded using OpenAI's text-embedding-3-small (768 dimensions) and stored in PostgreSQL with pgvector. When users upload their resume, it's embedded and matched using cosine similarity. The frontend shows match percentages and allows sorting by relevance.
Interesting Challenges
LinkedIn aggressively rate-limits automated requests. The data pipeline runs in constrained bursts with exponential backoff. The site still works with preloaded job data from peak crawling periods.
Extracting consistent metadata from varied job descriptions required prompt engineering. DSPy's structured outputs helped, but edge cases still produce inconsistent results.
What I'd Do Differently
The resume embedding approach treats the entire document as one vector. Chunking the resume (skills section, experience section, projects) and matching against corresponding job sections could improve relevance.
Key Features
- -Vector similarity resume-to-job matching
- -AI-powered job metadata extraction (GPT-4o-mini)
- -LinkedIn API integration
- -Advanced filtering by workplace, region, experience level
- -Analytics dashboards for market insights
Tech